很多企业现在都想让 AI 帮忙找资料。
销售想让它快速调客户案例,法务想让它翻合同模板,客服想让它找标准答复,研发想让它定位历史方案和技术文档。表面看,这只是把原来的“搜索文件”升级成“用 AI 找文件”。
但企业真把这件事往前推进,很快就会发现,一个比模型效果更基础的问题会先冒出来:谁能看、谁不能看?
因为 AI 帮你找资料,不是简单把文件名搜出来,而是会读取、理解、归纳,最后把内容重新组织成答案给到用户。如果这个过程没有建立在清晰的权限边界上,那么 AI 找得越快,越可能把不该给某个人看的资料更快送到他面前。
所以,企业想让 AI 真正帮忙找资料,第一步不是急着接模型,而是先把“谁能看、谁不能看”这件事回答清楚。
一、AI 找资料和传统搜索,看起来很像,本质上不是一回事
很多企业会觉得,原来员工也是在文件系统里搜索资料,现在只是把搜索框换成了 AI,对权限的要求应该差不多。
但真正的区别在于,传统搜索更多是“人自己找、人自己看、人自己判断”;AI 检索则会主动读取内容、理解语义、跨文档汇总,甚至把不同来源的内容拼接成一个更像“结论”的回答。
也就是说,传统搜索更多是把入口给人,AI 检索则是在替人完成一部分阅读、筛选和整合工作。
这就带来一个非常现实的问题:
如果底层权限边界本来就不清楚,AI 就不只是“多搜到几个文件”,而是可能把原本不该被一起看到的信息重新组织后讲出来。
比如销售想找一个制造业客户案例,AI 在检索过程中如果顺带读到了历史报价底稿、合同修改记录、售后问题说明,最后再汇总成一个“给销售的回答”,那风险已经不是“看错一个文件”,而是把多个敏感信息点一起带了出来。
二、企业真正缺的,往往不是一个会找资料的 AI,而是一套能承接 AI 的文件底座
很多团队一做 AI 项目,第一反应就是接模型、搭知识库、做问答,看起来路线没有问题。但如果企业底层资料本来就散,目录本来就乱,权限本来就模糊,那么 AI 接得越快,旧问题暴露得越快。
这也是为什么很多企业做完第一轮测试后,会发现 AI 效果不是唯一问题,甚至不是最难的问题。真正难的是,资料到底是不是在一个可控的体系里。
赛凡智云这类企业级文件平台的价值,就恰恰体现在这里。
它不是单纯帮企业“把文件集中存起来”,而是先把文件放进一个有规则的底座里。目录怎么分、资料怎么沉淀、不同人能看什么、哪些能下载、哪些能外发、哪些操作要审计,这些问题本来就应该在文件平台层先被解决。
只有底层先变得可控,AI 在上面做检索、问答和归纳时,才不会一上来就踩权限问题。
三、想让 AI 帮忙找资料,企业至少要先把三件事说清楚
很多企业以为,AI 找资料最核心的是“能不能找全”。其实在企业环境里,更重要的不是找得多全,而是找得是否合规、是否在边界内。
真正落地前,至少要先把三件事定义清楚。
1. 谁能检索哪些资料
销售、法务、研发、客服即使都在使用同一个 AI,也绝不意味着他们应该共享同一份可读资料范围。
销售可能只该看客户案例、产品方案和已批准的报价参考;法务可以看合同模板、条款版本和审批记录;研发可以看技术文档、图纸和项目沉淀。AI 如果不能继承这种组织边界,就会把原来的人和部门边界打穿。
这也是为什么 AI 不应该拿一个“公共高权限账号”去全库检索,而应该跟着当前用户身份走。谁在发起请求,AI 就按谁的权限范围去找。
2. 谁能看到什么层级的结果
不是所有能被检索到的内容,都适合被原文展开给用户。
有些内容可以被摘要,但不适合直接展示全文;有些资料可以在项目组内部看,但不能直接被复制到跨部门场景;有些文件可以检索到存在,但下载、外发、转述都应该被限制。
换句话说,企业不能只管“能不能搜到”,还要管“搜到以后能展示到什么程度”。AI 输出结果本身,也必须被纳入权限边界里。
3. 谁的调用过程必须被留痕
AI 不是读完就算了,企业后续还要能追溯:是谁发起了这次检索,它读取了哪些资料,是否碰到过敏感目录,最终回答里有没有引用不该出现的内容。
尤其当 AI 开始接触合同、客户资料、方案库、投标文档这类敏感内容时,调用过程如果没有审计链路,后面一旦出了问题,企业往往只能看到结果,却看不到路径。
所以,AI 找资料这件事,最终一定会落到审计与追溯能力上。
四、赛凡智云能帮企业把“谁能看、谁不能看”真正落到系统里
从 AI 落地视角看,赛凡智云的意义不只是企业云盘,也不只是文件集中存储,而是它能提供一套适合 AI 场景的底层文件治理能力。
更具体地说,主要体现在几个层面:
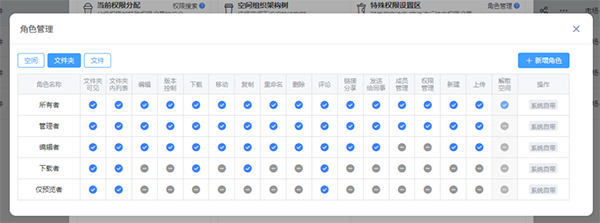
细粒度权限控制
赛凡支持按部门、岗位、项目、角色做精细化权限划分,不同人员可分别设置查看、上传、下载、编辑、删除、分享、外发等权限。
这意味着,AI 接入时不需要重新发明一套“AI 专属权限”,而是可以建立在原有权限体系之上。
统一目录与资料治理
企业资料不再散落在员工电脑、微信群、邮件附件、第三方网盘和零散共享盘里,而是统一沉淀在一个可管理的平台中。只有资料先被规范管理,AI 才能在清晰边界里发挥作用。
审计与追踪能力
谁看了什么、什么时候查看、是否下载、是否外发,本来就是企业文件管理要解决的问题。AI 接入后,这种能力只会变得更重要,因为企业还会进一步关心:这次 AI 回答引用了哪些资料,是否触达过敏感内容。
安全共享与外发控制
很多资料不是完全不能共享,而是必须在可控条件下共享。赛凡可以对分享链接设置有效期、提取码、访问次数、下载限制等规则,让对外协作仍然保持在企业可接受的范围内。
私有化部署与数据可控
对于数据安全要求高的企业来说,AI 不是不能上,而是不能建立在不可控的数据环境之上。赛凡支持私有化部署,让核心资料、权限逻辑和访问记录始终掌握在企业自己手里。
五、AI 想真正帮企业找资料,前提不是更会找,而是先学会守边界
很多企业今天谈 AI,容易把重点放在“它能不能帮我更快找到资料”。
但从业务落地角度看,更重要的问题其实是:它在帮我找资料的时候,是否仍然遵守原来的权限规则、资料边界和审计要求?
如果不能,那么这个 AI 找得越快,组织风险反而越大。因为企业要的不是一个什么都能翻出来的工具,而是一个在组织规则内工作、真正能进入业务流程的智能助手。
所以,企业想让 AI 帮忙找资料,先回答“谁能看、谁不能看”,不是多此一举,而是整件事能不能落地的前提。
结语
AI 检索看起来像是在提升搜索效率,实际上考验的是企业底层文件治理能力。
谁能看什么、谁不能看什么,哪些资料可以被检索,哪些只能在授权后访问,哪些答案可以输出,哪些内容必须被限制,这些问题如果不先想清楚,AI 越深入业务,后续返工和风险就越大。
真正成熟的路径,不是先把 AI 接上再说,而是先把文件、权限、目录、审计和外发规则打磨清楚,再让 AI 建立在这套基础之上发挥价值。
赛凡智云的价值,也正在这里。它不是单纯帮企业把资料存起来,而是在 AI 时代,帮企业把资料访问边界、权限控制能力和审计治理能力真正建立起来。
🌐 访问官网:赛凡智云官网
如果你也在推进 AI 检索、AI 知识库或 AI Agent 接入,不妨先从文件权限和资料边界梳理开始,往往会比一上来追求“全量可搜”更稳。
🏢 赛凡智云 — 企业私有云存储专家
安全可控 · 高效协同 · 一键部署 · AI就绪
数据安全可控
私有化部署,数据不出企业
AES-256加密 + 等保三级
精细权限管控
部门/角色/文件夹多级权限
操作审计全程追溯
全终端覆盖
PC/手机/平板/Web
随时随地安全访问
极速传输
大文件秒传,断点续传
局域网传输速度拉满
在线协同编辑
Office/WPS在线编辑
多人协作实时同步
AI数据底座
统一数据汇聚与管理
为企业AI应用夯实基础