2026年,企业自建或微调AI模型已经不是新鲜事了。从客服智能问答到合同智能审查,从产品推荐到质量检测——越来越多企业开始把AI从”看别人用”变成”自己上”。但几乎所有踩过坑的团队都会告诉你同一句话:模型不是最难的,数据才是。
训练数据从哪来?怎么存?怎么管版本?怎么控制谁能用?这些问题不解决,AI项目大概率烂尾。而这些问题的答案,都指向同一个基础设施——企业私有云存储。

一、AI训练数据面临的4个现实问题
1. 数据散落各处,收集成本高
要训练一个企业知识问答模型,你需要的数据可能分布在:内部文档库、邮件系统、客服工单系统、CRM、微信聊天记录、各种Excel表格……光是把这些数据收集到一起,就已经耗掉项目一半的时间。
2. 数据版本混乱
训练数据不是一成不变的。标注团队每天都在修改标注结果,业务部门也在持续更新文档。”这次训练用的是哪个版本的数据集?”——如果答不上来,模型出了问题就无法溯源。
3. 数据安全与合规
训练数据里可能包含客户隐私信息、商业机密、员工个人数据。把这些数据上传到第三方AI平台训练,合规风险极大。2026年数据合规要求越来越严,数据出企业边界就可能触碰红线。
4. 数据访问权限不清
AI团队、标注团队、业务部门——谁能看到哪些训练数据?标注人员能不能把数据下载到本地?这些权限如果不做细分,数据泄露只是时间问题。
二、私有云存储在AI训练中的3个关键角色
角色一:数据归集中心——把散落的数据收拢到一个地方
私有云存储的第一个价值是提供一个统一的数据归集平台:
- 各部门的业务文档通过同步客户端自动汇聚到云端
- 历史数据(邮件附件、项目文件、客服记录)批量导入
- 通过API对接其他业务系统,自动采集增量数据
- 按项目/数据集/任务建立清晰的目录结构
数据归集到一个平台后,AI团队不需要到处找数据,直接从云存储中读取即可。这一步看似简单,实际上能节省30%-50%的数据准备时间。
角色二:版本管理引擎——让每次训练可追溯
企业级私有云存储天然支持文件版本管理,这在AI训练场景中特别关键:
- 数据集版本化:每次修改标注数据自动保存新版本,保留完整变更历史
- 训练快照:在每次训练开始前,对使用的数据集做快照标记,确保可复现
- 回滚能力:发现最新数据集有问题?一键回滚到上一个版本重新训练
- 变更记录:谁在什么时间修改了什么文件,全程留痕
这种能力和文件版本管理与恢复的核心逻辑一致,只是应用在了AI训练这个特定场景。
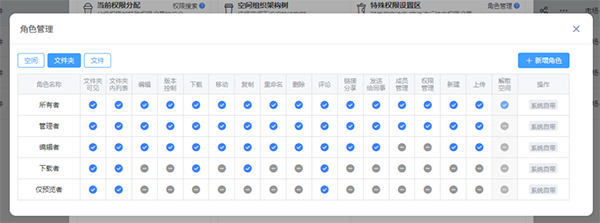
角色三:安全访问层——让数据”用得到但拿不走”
AI训练场景对数据权限有独特需求:
- AI训练服务器需要能读取数据(通过API或挂载),但不应该有删除权限
- 标注团队需要能编辑标注文件,但不应该能下载原始数据
- 业务部门只能上传数据,不能看到其他项目的训练数据
- 外部标注外包只能在线查看和标注,绝不能导出
私有云存储的细粒度权限管控正好满足这种复杂的权限需求——查看、编辑、下载、外发分别控制,精确到文件级别。
三、为什么必须是”私有云”而不是公有云?
有人会问:用阿里云OSS或者AWS S3不行吗?对于AI训练数据管理,私有化部署有不可替代的优势:
| 维度 | 公有云存储 | 私有云存储 |
|---|---|---|
| 数据位置 | 服务商机房 | 企业自己的服务器 |
| 训练数据安全 | 上传到外部有合规风险 | 数据不出企业边界 |
| 内网传输速度 | 受公网带宽限制 | 千兆/万兆内网直传 |
| 大数据集成本 | 按量付费,TB级很贵 | 硬盘扩容即可,成本低 |
| 与本地GPU服务器对接 | 需要下载到本地 | 内网直接挂载读取 |
特别是当企业有自己的GPU训练服务器时,训练数据放在内网的私有云存储上,通过NFS/SMB直接挂载读取,速度和安全性都远优于从公有云下载。

四、赛凡智云:为AI时代设计的数据底座
赛凡智云的定位就是”AI前数据底座“——帮企业在上AI之前把数据地基打好:
- 统一归集:支持多源数据导入,一个平台管理所有非结构化数据
- 版本管理:自动版本、变更记录、快照回溯,训练数据全程可追溯
- 细粒度权限:AI服务器、标注团队、业务部门分级授权
- 开放API:RESTful API + WebDAV + SMB,AI训练脚本直接读写
- 私有化部署:数据在自己服务器上,训练过程不出内网
- 弹性扩容:从TB到PB按需扩展存储空间
五、实操路径:4步搭建AI训练数据管理体系
- 数据归集(第1周):部署赛凡智云,把各处散落的业务数据统一迁入
- 数据治理(第2-3周):建立分类体系、清理重复和无效数据、补充标签
- 权限设置(第3周):按角色配置数据访问权限,AI训练相关数据集单独隔离
- 对接训练(第4周):通过API/挂载方式,让训练服务器直接读取数据
一个月内即可完成基础设施搭建,后续持续优化即可。
六、总结
AI模型训练的瓶颈不在算法,在数据。而数据管理的瓶颈不在工具多不多,在有没有一个统一、安全、可追溯的数据底座。私有云存储正是这个底座的最佳载体——它解决了数据散落、版本混乱、权限失控这三大核心问题,让AI训练从”到处找数据”变成”打开平台就能用”。
👉 了解赛凡智云AI数据底座方案 | 申请免费试用
🏢 赛凡智云 — 企业私有云存储专家
安全可控 · 高效协同 · 一键部署 · AI就绪
数据安全可控
私有化部署,数据不出企业
AES-256加密 + 等保三级
精细权限管控
部门/角色/文件夹多级权限
操作审计全程追溯
全终端覆盖
PC/手机/平板/Web
随时随地安全访问
极速传输
大文件秒传,断点续传
局域网传输速度拉满
在线协同编辑
Office/WPS在线编辑
多人协作实时同步
AI数据底座
统一数据汇聚与管理
为企业AI应用夯实基础