现在很多企业都在讨论 AI,仿佛只要接入一个模型,效率就会自动提升,知识就会自动被唤醒,组织能力就会自动升级。但真正落地之后,很多团队会发现,AI 没有想象中那么神,甚至经常答非所问。
问题往往不在模型,而在资料本身。真正拉开企业差距的,可能不是会不会用 AI,而是资料是否值得被 AI 读取。

一、什么叫“资料值得被 AI 读取”
不是文件越多越好,也不是把历史文档一股脑喂进去就行。真正值得被 AI 读取的资料,至少要满足几个条件:
- 内容是有效的,不是过期制度、无效版本、重复材料。
- 结构是清晰的,知道它属于哪个部门、哪个项目、哪个场景。
- 权限是明确的,哪些资料能看、能引用、能对谁开放要有边界。
- 更新是持续的,不能今天接入一次,后面半年没人维护。
如果没有这些基础,AI 读到的只是企业自己的噪音。
二、为什么很多企业接了 AI,结果却并不理想
因为 AI 并不会自动替企业完成资料治理。内部资料如果本来就散、乱、旧、重复,模型只会把这些问题放大。
- 同一个制度有多个版本,AI 不知道该引用哪个。
- 关键资料散在个人电脑和聊天记录里,AI 根本读不到。
- 敏感文件没有清晰权限边界,AI接入风险难控。
- 部门资料命名和分类不统一,后续检索质量很差。
所以,AI 表现不好,很多时候不是“模型不聪明”,而是“企业提供的语料不靠谱”。
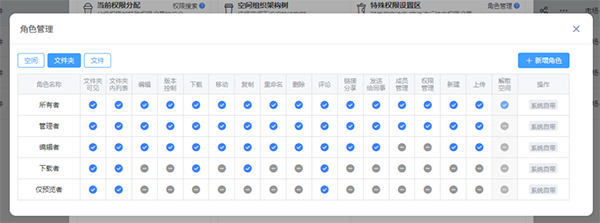
三、企业真正要补的,是 AI 之前的数据底座
AI 不是第一步,资料治理才是第一步。企业至少要先做三件事:
- 把重要资料收拢到统一平台,别继续散在微信群、个人网盘和本地磁盘里。
- 建立版本和分类规则,让资料具备被机器理解的基础。
- 把权限边界管起来,确保未来接入 AI 时可控、可审计。
谁先把这三件事做扎实,谁就更容易把 AI 真正变成生产力,而不是一个演示工具。
四、赛凡智云为什么适合作为 AI 之前的数据底座
赛凡智云的价值,在于先把企业资料放回一个统一、可控、可持续运营的环境里。
- 文件集中管理,减少关键资料散落和失控。
- 权限、搜索、版本、预览一起打通,方便后续接知识库和AI问答。
- 私有化部署能力更适合对数据主权和安全要求高的企业。
- 既能服务当下协作,也能为后续 AI 应用预留基础设施。
五、企业之间未来真正的差距,会先体现在资料质量上
短期内,大家接入的大模型差距不会太大,工具能力也会越来越趋同。真正能把结果拉开的,是谁家的资料更完整、更干净、更持续更新,也更适合被 AI 读取。
所以这场竞争,表面上看是 AI 竞争,本质上看还是数据底座竞争。谁先把资料变成高质量、可控、可复用的企业资产,谁就更有机会把 AI 用出真正的商业价值。
📎 相关阅读:未来淘汰一家公司的,可能不是 AI,而是它自己喂不出 AI、你以为公司在沉淀经验,其实大部分经验都死在聊天记录里
🌐 访问官网:赛凡智云官网
🏢 赛凡智云 — 企业私有云存储专家
安全可控 · 高效协同 · 一键部署 · AI就绪
数据安全可控
私有化部署,数据不出企业
AES-256加密 + 等保三级
精细权限管控
部门/角色/文件夹多级权限
操作审计全程追溯
全终端覆盖
PC/手机/平板/Web
随时随地安全访问
极速传输
大文件秒传,断点续传
局域网传输速度拉满
在线协同编辑
Office/WPS在线编辑
多人协作实时同步
AI数据底座
统一数据汇聚与管理
为企业AI应用夯实基础