这两年很多企业都在谈 AI-ready,但真正理解这四个字的人并不多。有人觉得买了模型接口就算准备好了,有人觉得搭个知识库、做个问答入口就够了。其实这些都只是表层动作。
如果企业内部的权限体系还是一团旧账,资料边界不清、共享逻辑混乱、审计能力薄弱,那就算模型接上了,也很难算真正 AI-ready。因为 AI-ready 从来不只是“能调用模型”,而是“企业资料是否已经进入可安全、可治理、可持续调用的状态”。
一、为什么权限体系决定 AI-ready 的成色
AI 落地的前提,是让系统能够稳定、合规地接触企业资料。可资料一旦接进来,谁能看、谁能调、谁能转、谁能下载,这些问题就必须先有清楚答案。没有权限体系打底,AI 只会建立在模糊边界上。
很多企业现在的问题不是没有数据,而是数据虽然在,却没有形成“可安全使用”的状态。文件散在多个系统里,目录结构历史叠加,共享规则因人而异,甚至连哪些资料应该纳入知识库、哪些资料应该只在特定角色间流转都说不清。在这种情况下,接模型只是把不确定性带入更高频的调用链路里。
所以 AI-ready 真正决定成色的,不是模型接得多快,而是底层权限体系能不能承受 AI 的持续调用。这一点也和企业要用AI,为什么必须先解决数据权限、隔离和安全边界问题的逻辑是一致的。
二、AI-ready 常被忽视的三块底层能力
很多企业谈 AI-ready 时,最容易忽略的不是模型能力,而是三块基础能力。
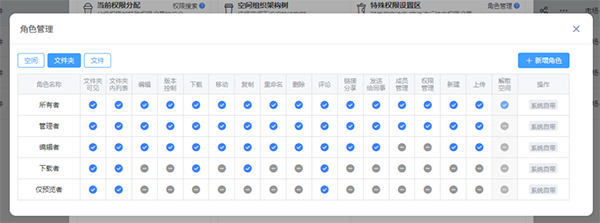
1. 权限分级
资料有没有按敏感度、部门属性、项目属性区分清楚。普通知识文档、客户资料、合同底稿、经营数据,本来就不应该用同一种开放逻辑来管理。
2. 访问控制
不同角色访问文件时,是不是有清楚的查看、编辑、下载、分享边界。能看到不等于能带走,能调取不等于能传播,这在 AI 场景里尤其关键。
3. 审计留痕
系统有没有把关键访问和操作记录下来。AI 调用了什么资料、生成了哪些输出、触达过哪些空间,这些记录如果没有留住,后面既难复盘,也难建立管理层信心。
如果这三块没补齐,企业接入 AI 后最容易遇到的不是“模型不够聪明”,而是“系统不敢真正放开用”。
三、为什么很多企业越想快上 AI,越容易卡住
因为前期大家都盯着演示效果,容易忽略底层治理。等到真的想把 AI 用进业务里,才发现权限模型太粗、共享盘太乱、目录太旧、审计太弱,最后不得不回头补基础。这时候不但慢,还很容易影响内部信心。
更现实的一点是,业务部门往往希望 AI 快速进入日常流程,但 IT 和管理层通常更在意边界是否安全、风险是否可控。只要权限体系没有准备好,AI 项目就很容易停留在试用、演示和局部实验阶段,迟迟走不到真正常态化使用。这也是为什么很多企业表面上已经“接上大模型”,但实际上离 AI-ready 还有一段距离。
如果你已经发现企业一接 AI,很多旧的权限问题就被放大,其实可以反过来看这不是坏事,因为它说明底层问题终于被摆到了必须处理的位置上。这和为什么很多企业一接 AI,就暴露出权限管理老毛病讲的是同一类现象。
四、赛凡更适合承接的,不只是存储,而是AI前的文件与权限底座
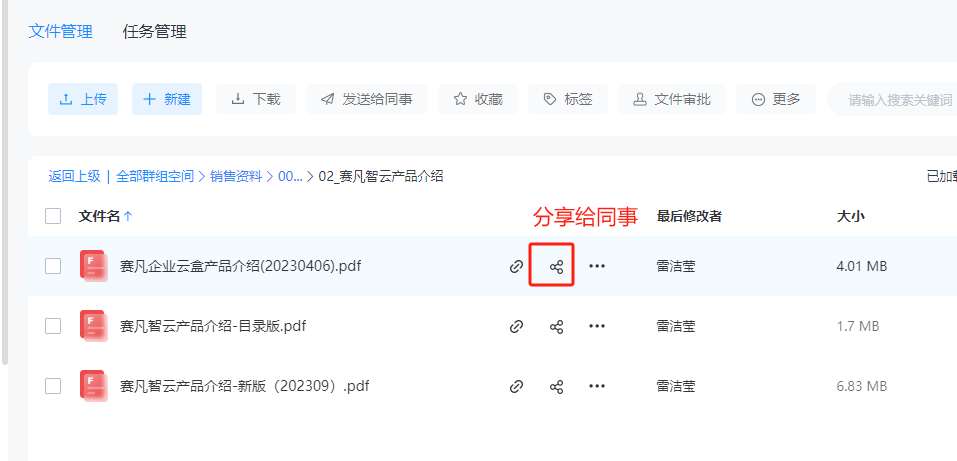
赛凡企业云盒更适合拿来做 AI-ready 的文件和权限底座。它不是单纯提供一个存储空间,而是能把企业常见的文件管理、共享、协作、权限、外链和审计整合在一起,让后续接知识库、接 AI Agent 时有更清楚的边界。
从企业视角看,赛凡更有价值的地方主要体现在:
- 统一资料入口,减少文件散落在多个工具中的治理成本。
- 权限控制更细,能够围绕组织、角色、项目和动作建立更清楚的边界。
- 共享链路更可控,适合把内部协作与外部分享分开管理。
- 审计和追溯更完整,为 AI 调用和资料使用建立可信记录。
- 更适合作为 AI 前的数据底座,先把文件和权限理顺,再去谈智能接入,后续会顺很多。
这也是为什么赛凡不是简单的“云盘替代”,而更像是企业把 AI 用稳、用深之前的一层基础建设。先把文件底座和权限底座搭起来,AI 落地才更容易从试用走向常态化。
五、常见问题 Q&A
Q1:接上大模型接口,为什么还不能算 AI-ready?
因为模型接口只是能力入口,不代表企业内部资料已经准备好被安全调用。没有权限、共享和审计底座,模型接上也很难长期稳定运行。
Q2:AI-ready 最容易被忽略的地方是什么?
最容易被忽略的是权限分级、访问控制和审计留痕。很多企业以为这些是后期细节,实际上它们决定了 AI 能不能真正进入业务。
Q3:赛凡在这一步里的核心价值是什么?
核心不是单纯存文件,而是帮助企业把文件、权限、共享和审计放进统一规则里,为后续知识库、问答和 Agent 接入提供稳定底座。
Q4:企业应该先做 AI,还是先补底层治理?
更稳妥的路径是先把资料体系、权限体系和共享边界理顺,再逐步扩大 AI 使用范围。这样项目推进更快,返工也更少。
所以 AI-ready 真正该看的,不只是有没有接上大模型,而是这套权限体系能不能支撑 AI 长期稳定地跑下去。
🌐 访问官网:赛凡智云官网
如果你也在推进企业 AI 落地,不妨先把文件和权限底座补齐,再决定模型要接到多深、跑到多广。
🏢 赛凡智云 — 企业私有云存储专家
安全可控 · 高效协同 · 一键部署 · AI就绪
数据安全可控
私有化部署,数据不出企业
AES-256加密 + 等保三级
精细权限管控
部门/角色/文件夹多级权限
操作审计全程追溯
全终端覆盖
PC/手机/平板/Web
随时随地安全访问
极速传输
大文件秒传,断点续传
局域网传输速度拉满
在线协同编辑
Office/WPS在线编辑
多人协作实时同步
AI数据底座
统一数据汇聚与管理
为企业AI应用夯实基础